记录下如何监控JVM,包括JVM的线程、堆内存、CPU使用情况等
GC LOG
GC日志能够反应JVM内存的动态分配回收状况、应用停顿的时间,是GC调优的依据
JVM配置查询
jmap -heap [pid]
1 | Mac:dmz-inward- mac$ jmap -heap 1016 (JDK1.8) |
记录下如何监控JVM,包括JVM的线程、堆内存、CPU使用情况等
GC日志能够反应JVM内存的动态分配回收状况、应用停顿的时间,是GC调优的依据
jmap -heap [pid]
1 | Mac:dmz-inward- mac$ jmap -heap 1016 (JDK1.8) |

JVM到底怎么优化啊?优化什么?为啥要优化。。?
大家都知道JVM中的堆内存是分代的结构,来看看堆内存的开辟与回收的细节
堆内存在Minor GC 与 Full GC发生的时候回收,那么Minor GC 、Full GC 什么时候发生呢。。

怎么对数据进行排序?排序算法有多种,该使用哪种排序算法呢?回顾下时间复杂度较低的归并排序
归并排序的核心分为两个部分。1。将待排序数据对半分,直到只剩一个元素。2。针对两部分的数据(每部分已经是有序的)进行排序,左半部分与右半部分进行排序
1 | public void mergeSortByRecursive(int[] data) { |

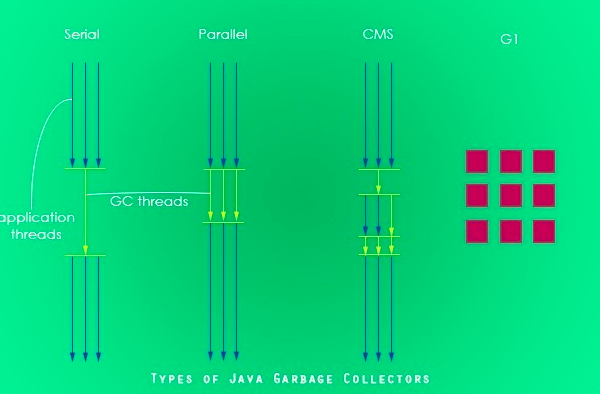
垃圾回收器是内存回收的具体实现,Java有四类垃圾回收器,分别是:
- Serial Garbage Collector
- Parallel Garbage Collector
- CMS Garbage Collector
- G1 Garbage Collector
1 | // 通过如下命令可以查看 JVM 默认的垃圾回收器 |
串行垃圾回收器是JVM Client模式下的默认GC,只使用一个单独的线程进行垃圾回收,垃圾回收时会冻结所有应用程序的线程,垃圾回收期间程序暂停的时间较长
Serial GC为新生代的垃圾搜集器,采用复制回收算法。Java中所有新产生的对象都在Yong区中的Eden区,当Eden区的大小不足以容纳新生的对象或对象大小超过了PretenureSizeThreshold的参数配置大小 ,对象只能在Old区分配。当Eden区满后会触发Minor GC ,触法Minor GC前需要检查老年代的连续空间是否大于新生代总大小或者历届晋升对象的平均大小,若满足就会进行Minor GC,否则将进行Full GC。Minor GC除了清除Eden区的非活跃对象外,还会把Survivor区一些老对象移动到Old区,老对象的定义通过配置MaxTenuringThreshold大小来控制,1.当对象在Survivor区的存活次数达到MaxTenuringThreshold的大小则会被移动到Old区。 2.当Survivor区中相同年龄大小的所有对象大小总和超过了Survivor区空间的一半(默认 -XX:TargetSurvivorRatio=50)则会被移动到Old区
Serial Old GC 为老年代搜集器,使用“标记-整理”算法,此GC不能够主动配置。1.当CMS收集器发生错误的时候使用。2.配合其他GC使用

在Java开发的过程中,程序的执行需要计算机内存空间,Java并没有语法与内存创建、释放有直接联系,JVM负责管理内存的申请与释放,对于Java语言来说,显示的内存申请通常有两种:静态内存分配与动态内存分配
- 静态内存分配:Java类或方法中的原始类型数据和对象的引用都是静态分配的内存,当Java编译器执行编译后就已经确定了静态内存的大小,在程序被加载后会分配静态内存且在程序运行期间内存大小不会再改变
- 静态内存回收:程序执行结束后释放、方法执行结束后释放
- 动态内存分配:Java中的对象类型的数据创建是动态的内存分配,只有在程序执行的过程中才知道程序所需的内存大小
- 动态内存分配:Java中的对象不再被使用的时候内存会被回收
- 什么样的对象应该被认为是垃圾需要回收?对象是否是垃圾对象取决于对象的引用类型与对象是否根路径可达
- 如何回收垃圾对象释放内存?由垃圾回收算法负责
- 对象与根节点之间的联系称为引用链,当对象与根节点之间不存在引用链时,此对象成为垃圾对象,根节点可以是以下元素
- 在方法中局部变量区的对象引用
- 在Java操作栈中的对象引用
- 在常量池中的对象引用(如常量池中引用的的类名String在堆中
- 在本地方法的对象引用
- 类的Class对象(JVM加载Class时,会在堆中创建一个代表这个类的唯一数据类型的Class对象
- 若对象被软引用,当内存不足时,软引用对象为垃圾对象
- 若对象被弱引用,则此对象为垃圾对象
- 若对象被虚引用,则此对象为垃圾对象

记录 Java中的堆与栈究竟是什么,JVM在计算机物理内存中是如何工作的
计算机中存在不同类型的内存包括:RAM,CPU寄存器,缓存CACHE等
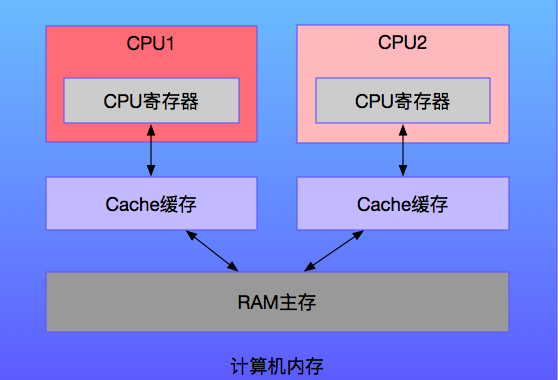
物理内存一般指的是RAM与存储器,CPU与RAM或寄存器通信依靠的是地址总线。总线的宽度决定了CPU与内存间通信的数据量。如32位的地址总线寻址范围为:0x00000000~0xffffffff,即232个内存位置,每个内存位置会引用一个字节,所以232 byte = 4GB,计算机的内存是通过操作系统进行分配的,不同进程申请到的内存是逻辑上隔离的
操作系统按照进程管理内存的申请,进程间各自内存由操作系统保证独立性,独立性不表示一个内存空间只能由一个进程使用。虚拟内存使得不同进程间可以共享内存空间,然而逻辑上不同进程是不能互相访问内存的。当一个进程不活动的情况下,操作系统会将这个进程中的数据移动到磁盘文件中(Windows中的页面文件或者Linux中的swap区),当不活跃进程恢复则操作系统会把磁盘数据重新交换到物理内存中(磁盘IO开销远大于读内存,应该避免频繁的内存交换),而真正高效的内存留给活跃进程使用。若Linux中的swap区活跃度较高说明物理内存的已经不足,swap区被频繁使用会导致系统运行缓慢。虚拟内存提高了内存利用率,而且能够扩展内存的地址空间,如虚拟内存映射到物理内存、文件、其他存储设备上
- 内核空间:只要是操作系统运行时使用的用于程序调度、连接硬件资源等的操作逻辑
- 用户空间:程序真正能够使用的申请地址空间
通常网络传输的数据一般从内核空间传送到远端计算机的内核空间,然后将数据从内核空间复制到用户空间供用户使用,这种数据COPY是很耗时的(内核态到用户态的切换
JMM是JVM针对物理内存抽象出来的Java内存模型,是JVM在计算机内存中的工作方式。JVM按照Java运行时数据的存储结构定义Java内存模型

记录下自己对编码的理解和疑惑,什么是Unicode?UTF-8、UTF-16、ASCII又是什么?
编码 :信息从一种数据形式到另一种数据形式的转换过程。信息在计算机中的存储与传输是以二 进制的形式(010101)进行的,计算机中的存储单元为Byte,所以需要计算机处理的信息必须编码为Bytes。
解码:编码的逆向过程。计算机中为Bytes到字符信息的转换。
计算机中的存储单元为Byte即8位的二进制形式,所能表达的字符范围为28 = 256种,现存的字符远远多于256种,所以单个字节不足以存够如此多的字符。不同字符的表达是多样性的,不同地区使用不同的语言表达(字符编码),不同的语言自然有不同的字典解释(字符解码)。如何解码呢?byte c1=97代表什么字符?int c2= 26790 又该如何翻译呢?
ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16编码表中记录了不同字符的不同表达方式。是否存在不同字符的统一表达方式呢?即所有字符存在同一张编码表中。Unicode编码集保存着全世界的字符的编码点(CodePoint),可以存储足够多的字符表示。Unicode的编码形式又分为UTF-8,UTF-16,UTF-32分别表示8位,16位,32位存储。采用哪种编码需要在传输大小、编码效率等问题进行折中选择。UTF-8是可变长度的编码规则,一般会采用UTF-8进行编码,
Unicode的编码点以U+开始如U+0x0020的形式表示,能表示的编码点范围为0x0000 ~ 0x10FFFF。我们知道Java中的字符都是以Unicode的形式保存的,并且采用UTF-16的形式编码,所以说Java中的char占用16位即2个字节,16位所能存储的最大值为0xFFFF。那么对于U+10000~U+10FFFF部分的CodePoint(这一部分代表的字符被称为辅助字符supplementary character),Java中的UTF-16显然无法存储

简单记录下Docker集群swarm使用。
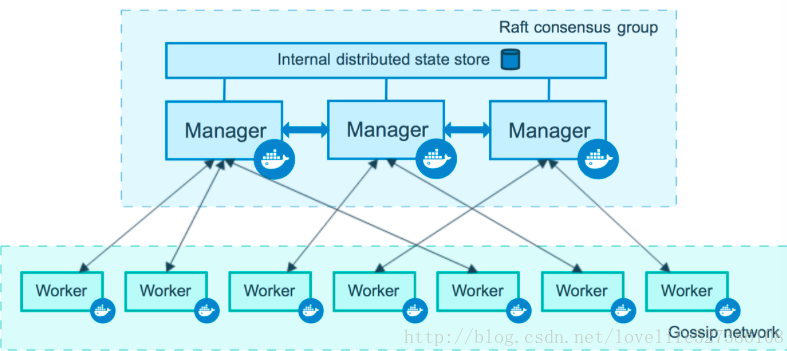
docker swarm模式可以让多个运行docker的机器加入集群管理,加入集群的docker机器被称为node。整个集群被node为manager的角色管理,其他的node角色则为workers,所有workers接受manager的指令行事
集群机器可以是物理机也可以是虚拟机,由于资源匮乏。本文只有一个 swarm node
- Manager Node:当发布service到swarm中(提交到管理节点),管理节点将service分发到Worker Node,工作节点接收到task开始工作
- Worker Node:工作节点接受来自管理节点分发的任务并执行,同时会将自己当前的状态通知到管理节点,管理者能够管理集群中节点的状态。Manager Node同时也可以是Worker Node
- 开启swarm模式:
docker swarm init- 离开swarm:
docker swarm leave --force- Node工作方式
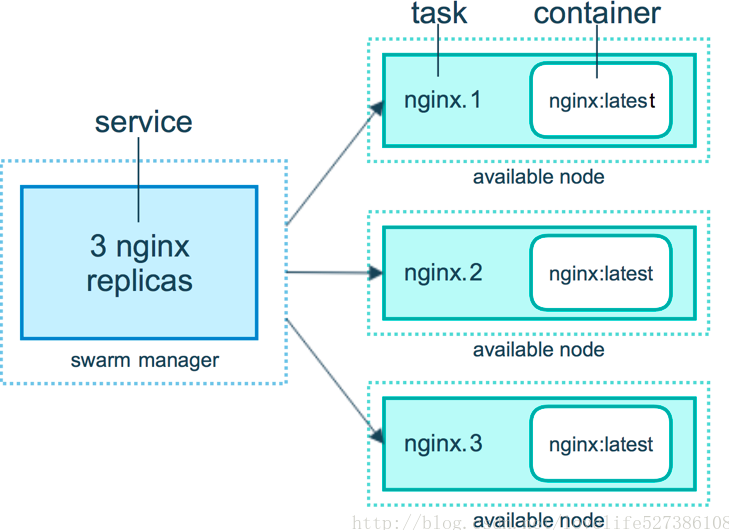
- Services:任务的定义,创建service有两种模式。
replicated services可以指定创建服务的副本数量由manager node分发到不同节点。global services模式的服务将在集群中所有节点上运行- tasks:任务是管理节点分发运行的单元
- 构建副本服务:
docker service create --replicas 3 --name web nginx,service只有在swarm模式下才能创建- 服务与任务的关系
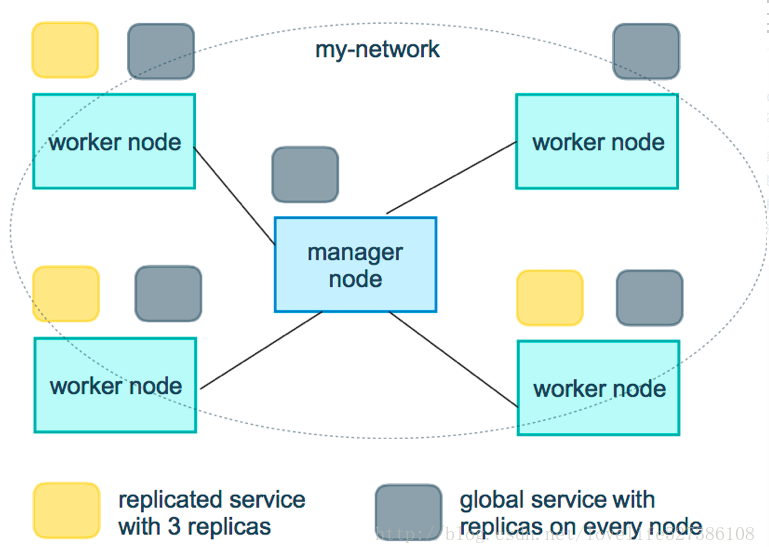
- replicated services和global services

简单记录下Docker容器的数据管理
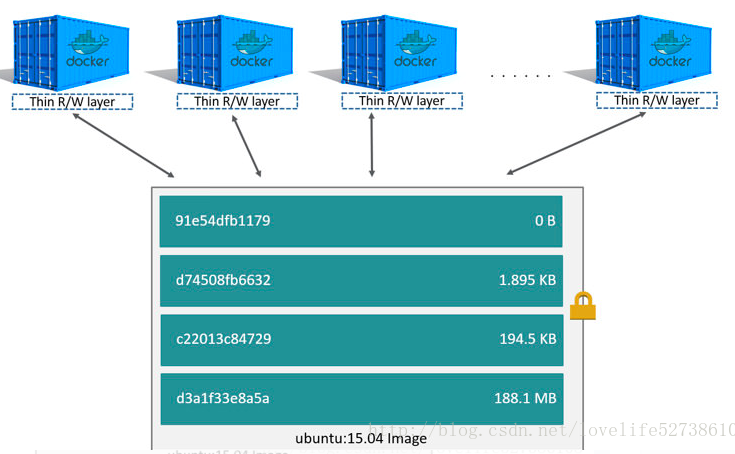
- Docker镜像是一层一层叠出来的,Dockerfile中的每一行指令都会产生一层,镜像中的数据对容器是只读的
- dockerfile中的命令可以直接访问底层(lower layer)已经产生的数据,当发生数据文件的修改时则会将底层文件复制到当前layer进行处理
docker history 镜像ID展示镜像组成结构- 存储结构图
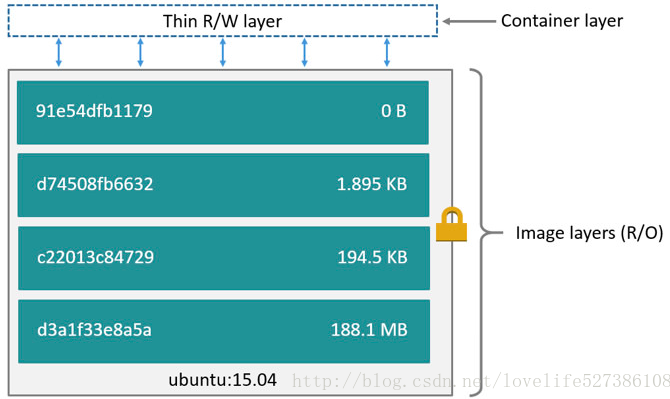
- docker的storage driver负责处理每层数据处理与存储
- Docker容器在镜像的基础之上又叠了一层(Container layer即Thin R/W层,每个容器都会有自己的Thin R/W层,镜像可以共享)
docker ps -s命令能够查看当前运行容器的大小- 当Container layer层发生数据文件的修改时则会将底层文件复制到当前layer进行处理即docker中的copy-on-write (CoW)策略,不同于虚拟机的本质。
- 存储结构图
- Container layer中的数据应该尽量的少,减少镜像大小,storage driver的引入同样会带来性能的下降并且在容器停止后数据将会消失。应该使用volumes(宿主机文件系统可持久化)