
Java 开发人员在构建高并发应用的时候,大部分都会依赖多线程进行开发,而在 Java 中,线程的启动、调度、销毁是由操作系统来执行的,使用成本很高,我们认为这是一种重量级的线程。Java 虚拟线程被 JEP425 提议作为预览功能,并在 JDK 19 中发布,它是一种轻量级线程,不与操作系统线程直接绑定,使用虚拟线程能够大大减少编写、维护和观察高吞吐量并发程序的工作量
Little’ Law
利特尔定律可以根据系统中项目的平均等待时间和每单位到达系统中的平均项目数量,来确定排队系统中的项目个数,公式如下
$L = λ * W$
- L:排队系统中的项目个数
- λ:每单位到达系统中的平均项目数
- W:项目的平均等待时间
服务器应用的扩展性受制于 Little’ Law 的约束,利特尔定律对应到服务器中的性能指标包括:响应时间、吞吐量、并发任务数,即
$并发任务数 = 吞吐量 * 响应时间$
假设系统的响应时间为 200ms,如果想要提高系统的吞吐量,公式给到的最直观的做法是提高系统的并发任务数,如何提高系统的并发数?最简单的做法是每个任务分配一个线程来处理。文章开始已经提到了 Java 中的线程是非常昂贵的,虽然池化线程可以降低线程创建、启动成本,但线程的数量仍然是有限的,并且每个线程的创建大概需要占用 2M 的内存,用于保存线程上下文,调用栈信息等
异步编程
线程在处理 I/O 等待的场景时会阻塞等待,在这期间的线程处于“无事可做”的状态,只有等到 I/O 返回结果,线程才会继续处理。因此我们可以让阻塞等待中的线程去处理其他的任务,这样可以提升线程的利用率,从而提高系统的吞吐量。异步编程可以在 I/O 等待的地方,释放这些阻塞的线程,从而去处理其他任务,当 I/O 返回结果的时候,线程再去处理响应结果,但是异步编程会打破编码的顺序性,因为请求的任务线程和处理 I/O 结果的线程,不属于同一个线程,这种编码风格使代码难于理解,并且线程栈信息的不连续,也导致代码难以调试,遇到问题更难定位
async/await
通过使用 async/await 语法方式,可以让编写的异步代码上下文有序,但它的结构与线程分开,需要通过其他构造形式将线程引入平台及依赖的工具包,所属生态适用需要花费很长的时间,与平台线程的绑定不够优雅
虚拟线程
虚拟线程是一种轻量级线程,它是一种用户模式线程,类似于 GoLang 中的协程。在早期的 Java 版本中,用户模式线程被称为 “green threads”,绿色线程出现在操作系统线程还未成熟阶段,那时候大多是单核系统,所有的绿色线程共享一个 OS Thread( M:1 scheduling)。Java 中的线程实现被称为平台线程,它是对系统线程的一比一包装(1:1 scheduling),虚拟线程与平台线程的关系则为 M:N 映射,M是大量的虚拟线程,N是少量的平台线程。虚拟线程运行在平台线程之上,当执行的任务被阻塞,虚拟线程对象会被从线程栈中拷贝到堆中,释放平台线程,当任务阻塞完成,虚拟线程会重新装载到平台线程中,如下两种情况中,虚拟线程不会释放平台线程
- 任务执行在 asynchronized 块或方法中
- 调用外部方法或 native 方法(JNI)
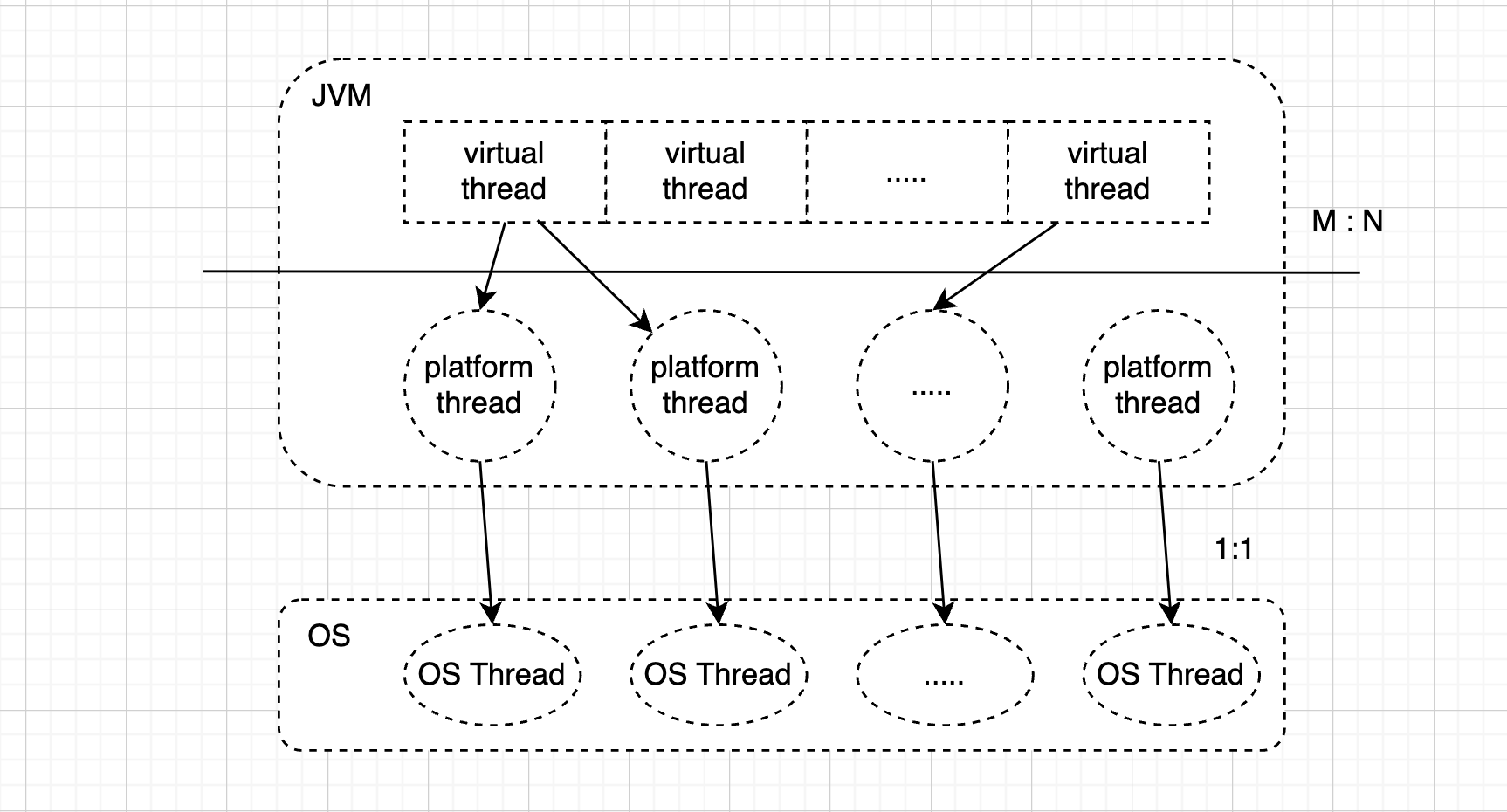
由于虚拟线程是轻量级的,所以我们可以为每一个任务分配一个独立的虚拟线程,从而提高系统的吞吐量
HTTP SERVER 基准测试
我们使用 OpenJDK11 自带的 HttpServer 来构建简单的 WEB 服务器功能,分别采用单线程(V1)、固定线程池(V2)、无界线程池(V3)和 虚拟线程(V4)的方式实现
V1(单线程)
单线程模式下基本没有吞吐量
1
2
3
4
5
6
7
8
9
10
11
| wrk -t100 -c200 -d30 http://localhost:18080/foo
Running 30s test @ http://localhost:18080/foo
100 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.03s 554.29ms 1.84s 55.56%
Req/Sec 0.59 1.28 5.00 85.81%
148 requests in 30.08s, 13.88KB read
Socket errors: connect 0, read 0, write 0, timeout 139
Requests/sec: 4.92
Transfer/sec: 472.36B
|
V2(固定数量线程池)
使用固定数量线程池的情况下,吞吐量也不高,所以在IO密集型任务下,线程池设置为 CPU核心数 * 2 不靠谱
1
2
3
4
5
6
7
8
9
10
11
12
| # 固定 10 个线程数
wrk -t100 -c200 -d30 http://localhost:28080/foo
Running 30s test @ http://localhost:28080/foo
100 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.03s 522.86ms 1.84s 55.56%
Req/Sec 0.70 1.37 6.00 88.58%
1480 requests in 30.07s, 138.75KB read
Socket errors: connect 0, read 29, write 0, timeout 1390
Requests/sec: 49.22
Transfer/sec: 4.61KB
|
V3(无界线程池)
每个请求一个线程,这种情况下的吞吐量比 V1、V2 好多了
1
2
3
4
5
6
7
8
9
10
11
| wrk -t100 -c200 -d30 http://localhost:38080/foo
Running 30s test @ http://localhost:38080/foo
100 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 220.58ms 19.78ms 279.31ms 66.81%
Req/Sec 8.80 1.66 20.00 85.00%
27116 requests in 30.11s, 2.49MB read
Socket errors: connect 0, read 33, write 0, timeout 0
Requests/sec: 900.67
Transfer/sec: 84.54KB
|
我们来试试用更强的压力来进行测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| wrk -t2000 -c2000 -d30 http://localhost:38080/foo
Running 30s test @ http://localhost:38080/foo
2000 threads and 2000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 254.27ms 175.67ms 1.70s 95.29%
Req/Sec 4.02 1.14 10.00 93.65%
98947 requests in 30.11s, 9.06MB read
Socket errors: connect 0, read 17267, write 1, timeout 709
Requests/sec: 3286.10
Transfer/sec: 308.09KB
# CPU、内存使用情况
CPU % MEM USAGE / LIMIT MEM %
32.60% 340.4MiB / 512MiB 66.48%
|
V4(虚拟线程)
我们来看看虚拟线程表现如何
1
2
3
4
5
6
7
8
9
10
11
12
13
| wrk -t2000 -c2000 -d30 http://localhost:48080/foo
Running 30s test @ http://localhost:48080/foo
2000 threads and 2000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 237.31ms 121.62ms 1.48s 96.29%
Req/Sec 4.10 1.03 10.00 80.37%
143827 requests in 30.11s, 13.17MB read
Socket errors: connect 0, read 31992, write 26, timeout 0
Requests/sec: 4776.83
Transfer/sec: 447.83KB
CPU % MEM USAGE / LIMIT MEM %
34.10% 161.8MiB / 512MiB 31.61%
|
测试数据显示吞吐量、内存使用情况都优于 V3 版本
参考
JEP 436
附录
获取 JVM 环境的堆和栈的大小
1
2
3
4
5
| java -XX:+PrintFlagsFinal -version | grep -Ei "maxheapsize|maxram|stacksize"
# MaxHeapSize = 134217728
# MaxRAMPercentage = 25.000000
# ThreadStackSize = 2048
|
获取容器CPU、内存、IO等使用情况
1
| docker stats {container_id}
|
获取 堆内存、GC 情况
1
| jstat -gcutil {pid} {interval} {count}
|
测试用例源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| HttpServer server = HttpServer.create(new InetSocketAddress(8080), 0);
server.createContext("/foo", (var t) -> {
try (OutputStream os = t.getResponseBody()) {
Thread.sleep(200);
byte[] response = "Hello World!".getBytes();
t.sendResponseHeaders(200, response.length);
os.write(response);
} catch (Exception e) {
e.printStackTrace();
}
});
server.setExecutor(Executors.newVirtualThreadPerTaskExecutor());
server.start();
|
docker-compose.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| version: '3.4'
services:
webserver_v1:
build:
context: .
dockerfile: v1.Dockerfile
ports:
- 18080:8080
deploy:
resources:
limits:
cpus: '2'
memory: 512M
webserver_v2:
build:
context: .
dockerfile: v2.Dockerfile
ports:
- 28080:8080
deploy:
resources:
limits:
cpus: '2'
memory: 512M
webserver_v3:
build:
context: .
dockerfile: v3.Dockerfile
ports:
- 38080:8080
deploy:
resources:
limits:
cpus: '2'
memory: 512M
webserver_v4:
build:
context: .
dockerfile: v4.Dockerfile
ports:
- 48080:8080
deploy:
resources:
limits:
cpus: '2'
memory: 512M
|