# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 8.54e-05 ...
global: scrape_interval: 120s # By default, scrape targets every 15 seconds. evaluation_interval: 120s # By default, scrape targets every 15 seconds. # scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'prometheus-test'
# Load and evaluate rules in this file every 'evaluation_interval' seconds. rule_files: # - "alert.rules" # - "first.rules" # - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' scrape_interval: 30s static_configs: - targets: ['host_ip:9090','host_ip:8080','host_ip:9100']
global: scrape_interval: 120s # By default, scrape targets every 15 seconds. evaluation_interval: 120s # By default, scrape targets every 15 seconds. # scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'monitoring'
# Load and evaluate rules in this file every 'evaluation_interval' seconds. rule_files: # - "alert.rules" # - "first.rules" # - "second.rules"
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' scrape_interval: 30s static_configs: - targets: ['localhost:9090','cAdvisor_service:8080','node_exporter_service:9100']
Life is like a roll of toilet paper. The closer it gets to the end, the faster it goes. - Forrest

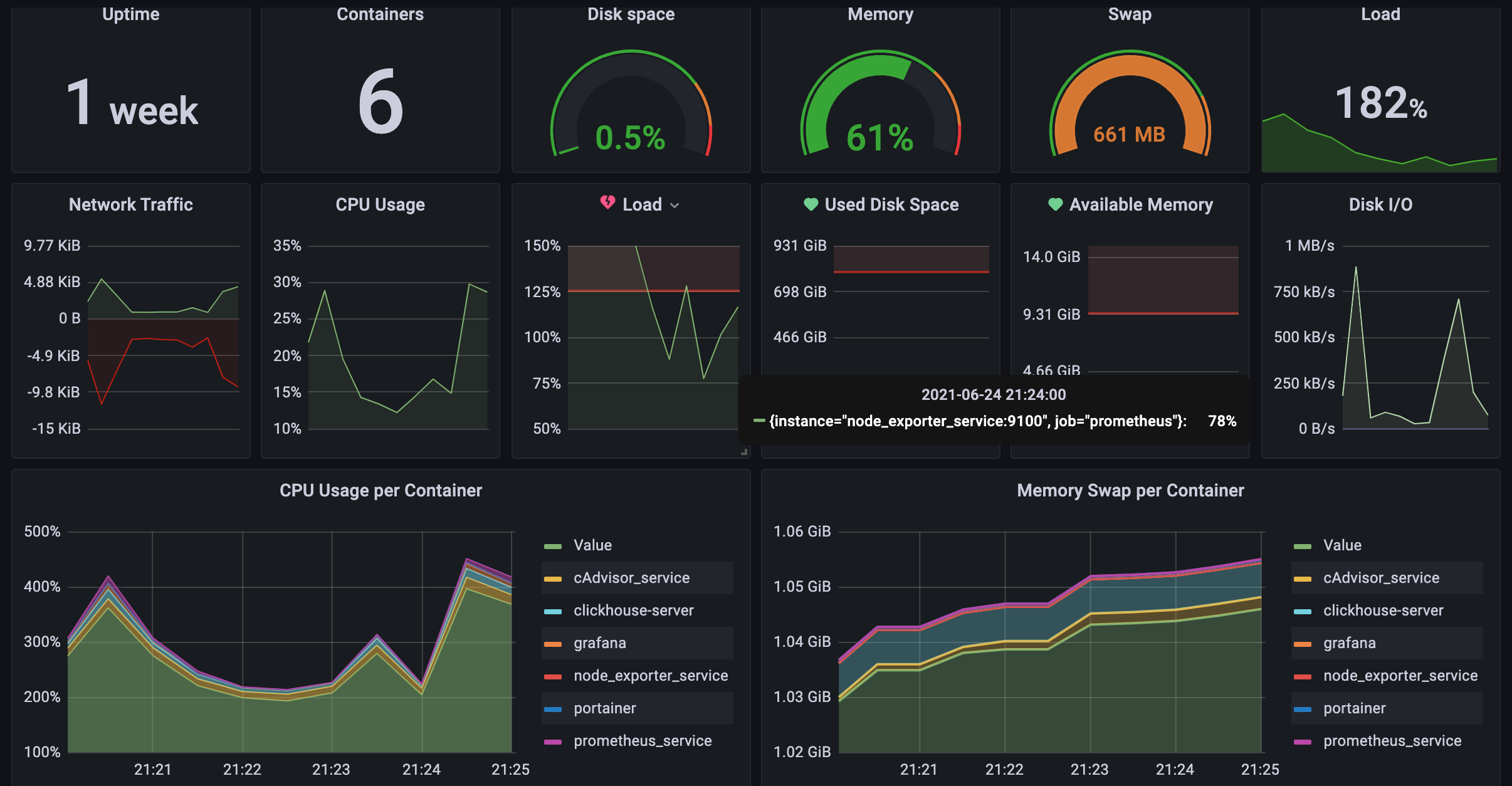 # 附录
# 附录